Inspecting gradients¶
This example assumes you’ve read advanced.ipynb, and covers:
- Inspecting gradients per layer
- Estimating good values of gradient clipping threshold
[1]:
import deeptrain
deeptrain.util.misc.append_examples_dir_to_sys_path()
from utils import make_autoencoder, init_session
from utils import AE_CONFIGS as C
from tensorflow.keras.optimizers import Adam
import numpy as np
Configure training¶
[2]:
C['traingen']['iter_verbosity'] = 0 # silence iteration printing since currently irrelevant
tg = init_session(C, make_autoencoder)
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
NOTE: will exclude `labels` from saving when `input_as_labels=True`; to keep 'labels', add '{labels}'to `saveskip_list` instead
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M3__model-nadam__min999.000
Expected gradient norm estimation¶
We iterate over entire train dataset, gathering gradients from every fit and computing and storing their L2-norms.
[3]:
grad_norms, *_ = tg.gradient_norm_over_dataset()
Computing gradient l2-norm over datagen batches, in inference mode
WARNING: datagen states will be reset
'.' = slice processed, '|' = batch processed
Data set_nums shuffled
||||||||||10||||||||||20||||||||||30||||||||||40||||||||
Data set_nums shuffled
GRADIENT L2-NORM (AVG, MAX) = (0.003, 0.003), computed over 48 batches, 48 datagen updates
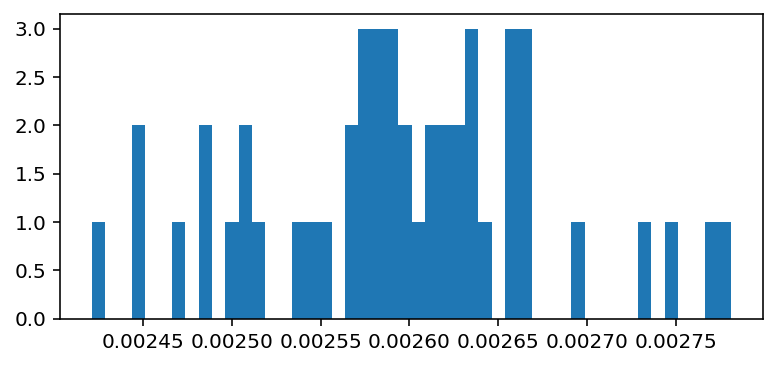
We can now restart training with setting optimizer clipnorm to 1.5x average value, avoiding extreme gradients while not clipping most standard gradients
[4]:
C['model']['optimizer'] = Adam(clipnorm=1.5 * np.mean(grad_norms))
tg = init_session(C, make_autoencoder)
tg.epochs = 1 # train just for demo
tg.train()
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
NOTE: will exclude `labels` from saving when `input_as_labels=True`; to keep 'labels', add '{labels}'to `saveskip_list` instead
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M4__model-Adam__min999.000
Data set_nums shuffled
_____________________
EPOCH 1 -- COMPLETE
Validating...
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M4__model-Adam__min.152
TrainGenerator state saved
Model report generated and saved
Training has concluded.
Complete gradient sum¶
This time we run a cumulative sum over actual gradient tensors, preserving and returning their shapes, allowing per-weight visualization
[5]:
plot_kw = {'h': 2} # double default height since we expect many weights
grads_sum, *_ = tg.gradient_sum_over_dataset(plot_kw=plot_kw)
Computing gradients sum over datagen batches, in inference mode
WARNING: datagen states will be reset
'.' = slice processed, '|' = batch processed
Data set_nums shuffled
||||||||||10||||||||||20||||||||||30||||||||||40||||||||
Data set_nums shuffled
GRADIENTS SUM computed over 48 batches, 48 datagen updates:
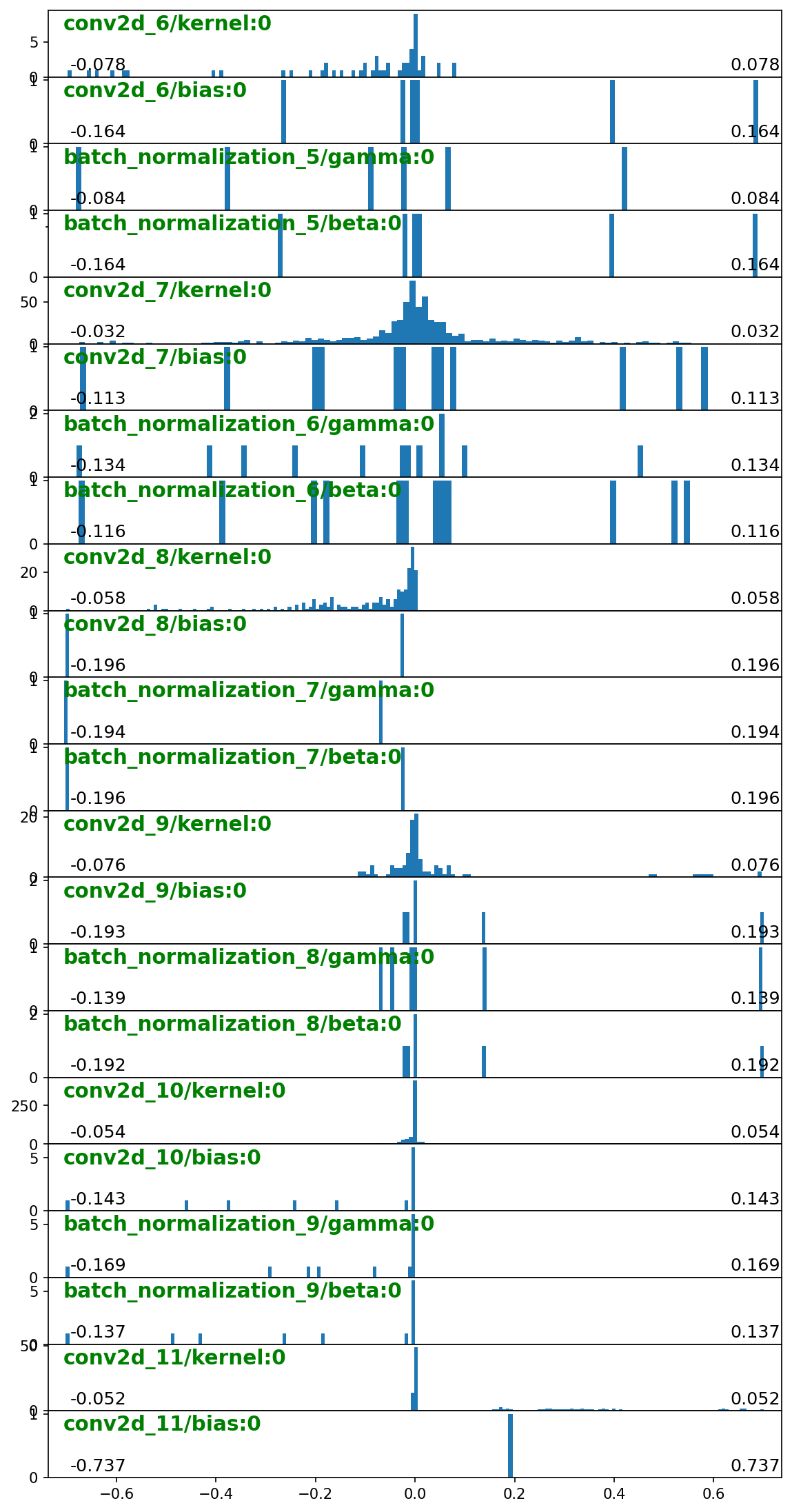
We can use the mean of grads_sum to set clipvalue instead of clipnorm.