Reproducibility¶
This example assumes you’ve read callbacks/basic.ipynb, and covers:
- Setting and restoring random seeds at arbitrary frequency for restoring from (nearly) any point in training
[1]:
import deeptrain
deeptrain.util.misc.append_examples_dir_to_sys_path() # for `from utils import`
from utils import make_classifier, init_session
from utils import CL_CONFIGS as C
from deeptrain.callbacks import RandomSeedSetter
Random seed setter¶
Sets new random seeds (random, numpy, TF-graph, TF-global) every epoch, incrementing by 1 from start value (default 0).
- Since
tg.save()is called each epoch, we specifyfreqvia'save'instead of'train:epoch'. - Setting
'load': 1makes the setter retrieve the loaded seed values (upontg.load()) and set seeds accordingly.
[2]:
seed_freq = {'save': 1, 'load': 1}
seed_setter = RandomSeedSetter(freq=seed_freq)
Configure & train¶
[3]:
C['traingen']['callbacks'] = [seed_setter]
C['traingen']['epochs'] = 3
C['traingen']['iter_verbosity'] = 0
tg = init_session(C, make_classifier)
Discovered 48 files with matching format
Discovered dataset with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
Discovered 36 files with matching format
Discovered dataset with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
Preloading superbatch ... Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M5__model-Adam__min999.000
[4]:
tg.train()
Data set_nums shuffled
_____________________
EPOCH 1 -- COMPLETE
Validating...
RANDOM SEEDS RESET (random: 1, numpy: 1, tf-graph: 1, tf-global: 1)
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M5__model-Adam__min1.232
RANDOM SEEDS RESET (random: 2, numpy: 2, tf-graph: 2, tf-global: 2)
TrainGenerator state saved
Model report generated and saved
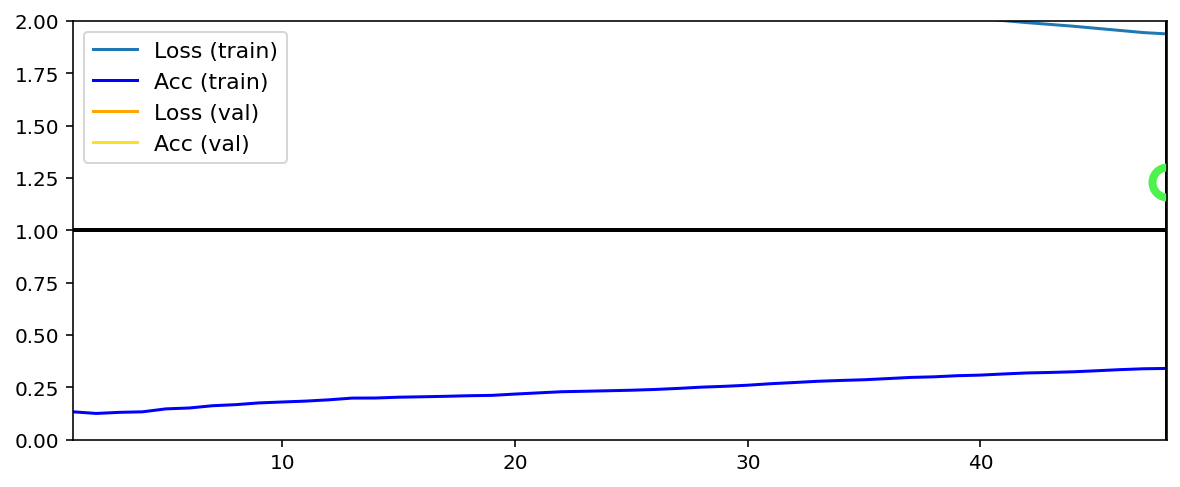
Data set_nums shuffled
_____________________
EPOCH 2 -- COMPLETE
Validating...
RANDOM SEEDS RESET (random: 3, numpy: 3, tf-graph: 3, tf-global: 3)
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M5__model-Adam__min.606
RANDOM SEEDS RESET (random: 4, numpy: 4, tf-graph: 4, tf-global: 4)
TrainGenerator state saved
Model report generated and saved
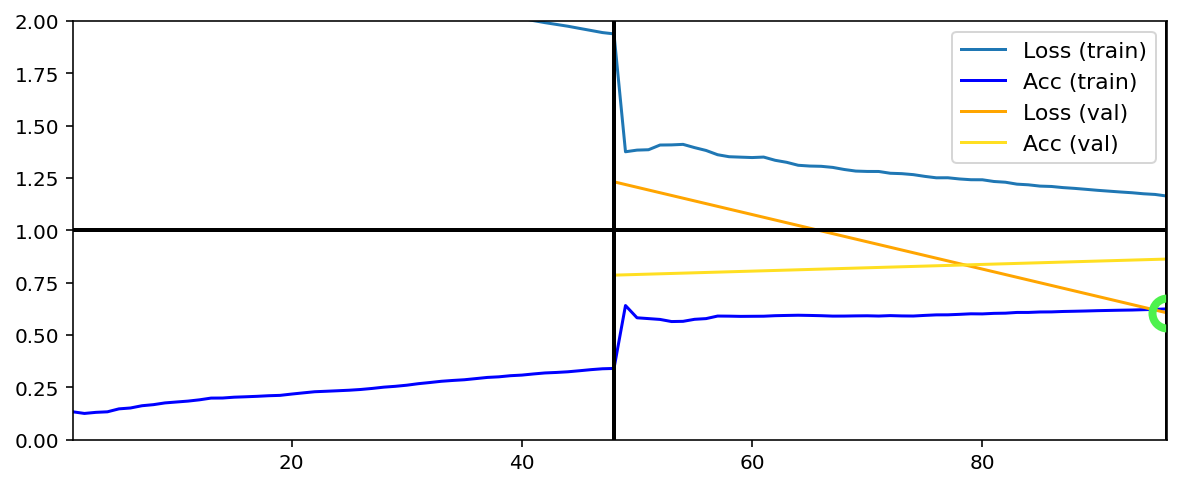
Data set_nums shuffled
_____________________
EPOCH 3 -- COMPLETE
Validating...
RANDOM SEEDS RESET (random: 5, numpy: 5, tf-graph: 5, tf-global: 5)
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M5__model-Adam__min.461
RANDOM SEEDS RESET (random: 6, numpy: 6, tf-graph: 6, tf-global: 6)
TrainGenerator state saved
Model report generated and saved
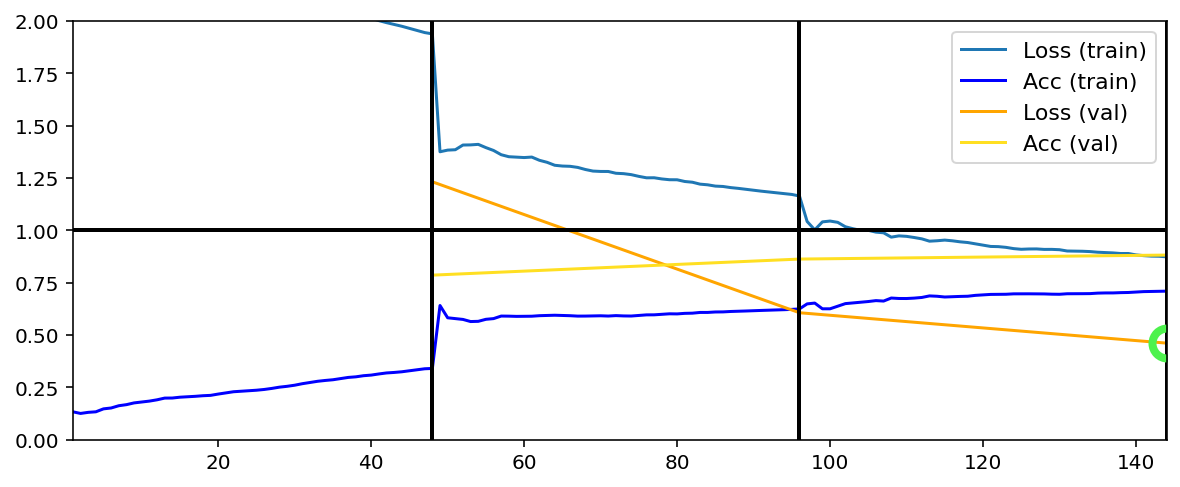
Training has concluded.
- Text printed after epoch shows the values each of the four random seedwere set to, which by default start at 0 and increment by 1.
- Double incrementing is due to
tg.save()being called within.checkpoint()and._save_best_model(). - Note that TensorFlow lacks a global random state for later recovery (though it’s possible to achieve with meticulous model & graph definition).
- Setting the seed at a point, and then loading the point and setting it again (which is what we’ll do), however, works.
Clear current session¶
[5]:
# Retrieve last saved logfile to then load
loadpath = tg.get_last_log('state')
tg.destroy(confirm=True)
del tg, seed_setter # seed_setter has internal reference to `tg`; destroy it
>>>TrainGenerator DESTROYED
Start new session, load savefile¶
[6]:
C['traingen']['loadpath'] = loadpath
C['traingen']['callbacks'] = [RandomSeedSetter(freq=seed_freq)]
tg = init_session(C, make_classifier)
Discovered 48 files with matching format
Discovered dataset with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
Discovered 36 files with matching format
Discovered dataset with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
TrainGenerator state loaded from C:\deeptrain\examples\dir\logs\M5__model-Adam__min999.000\M5__model-Adam__min.461_3vals__state.h5
--Preloading excluded data based on datagen states ...
Preloading superbatch ... Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
... finished--
RANDOM SEEDS RESET (random: 6, numpy: 6, tf-graph: 6, tf-global: 6)
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M6__model-Adam__min.461
Last random seed loaded and set; same would apply if we loaded from an earlier epoch.