Flexible batch_size & Faster SSD Loading¶
This example assumes you’ve read advanced.ipynb, and covers:
- How batch_size can be a multiple of batch_size on file
- Faster SSD loading via flexible batch size
[1]:
import deeptrain
deeptrain.util.misc.append_examples_dir_to_sys_path()
from utils import make_autoencoder, init_session, AE_CONFIGS as C
DeepTrain can use batch_size an integral multiple of one on file, by splitting up into smaller batches or combining into larger.
If a file stores 128 samples, we can split it to x2 64-sample batches, or combine two files into x1 256-sample batch.
[2]:
C['traingen']['epochs'] = 1
User batch_size=64, file batch_size=128¶
[3]:
C['datagen' ]['batch_size'] = 64
C['val_datagen']['batch_size'] = 64
C['model']['batch_shape'] = (64, 28, 28, 1)
[4]:
tg = init_session(C, make_autoencoder)
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
NOTE: will exclude `labels` from saving when `input_as_labels=True`; to keep 'labels', add '{labels}'to `saveskip_list` instead
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M3__model-nadam__min999.000
[5]:
tg.train()
Fitting set 1-a... Loss = 0.258925
Fitting set 1-b... Loss = 0.253132
Fitting set 2-a... Loss = 0.248714
Fitting set 2-b... Loss = 0.244794
Fitting set 3-a... Loss = 0.240528
Fitting set 3-b... Loss = 0.236792
Fitting set 4-a... Loss = 0.233093
Fitting set 4-b... Loss = 0.229193
Fitting set 5-a... Loss = 0.225168
Fitting set 5-b... Loss = 0.221404
Fitting set 6-a... Loss = 0.217777
Fitting set 6-b... Loss = 0.214355
Fitting set 7-a... Loss = 0.210822
Fitting set 7-b... Loss = 0.207650
Fitting set 8-a... Loss = 0.204442
Fitting set 8-b... Loss = 0.201394
Fitting set 9-a... Loss = 0.198212
Fitting set 9-b... Loss = 0.195283
Fitting set 10-a... Loss = 0.192382
Fitting set 10-b... Loss = 0.189485
Fitting set 11-a... Loss = 0.186594
Fitting set 11-b... Loss = 0.183790
Fitting set 12-a... Loss = 0.181016
Fitting set 12-b... Loss = 0.178265
Fitting set 13-a... Loss = 0.175732
Fitting set 13-b... Loss = 0.173159
Fitting set 14-a... Loss = 0.170662
Fitting set 14-b... Loss = 0.168275
Fitting set 15-a... Loss = 0.165887
Fitting set 15-b... Loss = 0.163576
Fitting set 16-a... Loss = 0.161341
Fitting set 16-b... Loss = 0.159190
Fitting set 17-a... Loss = 0.157046
Fitting set 17-b... Loss = 0.155032
Fitting set 18-a... Loss = 0.153119
Fitting set 18-b... Loss = 0.151234
Fitting set 19-a... Loss = 0.149326
Fitting set 19-b... Loss = 0.147504
Fitting set 20-a... Loss = 0.145753
Fitting set 20-b... Loss = 0.144026
Fitting set 21-a... Loss = 0.142380
Fitting set 21-b... Loss = 0.140762
Fitting set 22-a... Loss = 0.139213
Fitting set 22-b... Loss = 0.137701
Fitting set 23-a... Loss = 0.136231
Fitting set 23-b... Loss = 0.134775
Fitting set 24-a... Loss = 0.133367
Fitting set 24-b... Loss = 0.131993
Fitting set 25-a... Loss = 0.130666
Fitting set 25-b... Loss = 0.129385
Fitting set 26-a... Loss = 0.128131
Fitting set 26-b... Loss = 0.126897
Fitting set 27-a... Loss = 0.125704
Fitting set 27-b... Loss = 0.124558
Fitting set 28-a... Loss = 0.123391
Fitting set 28-b... Loss = 0.122320
Fitting set 29-a... Loss = 0.121234
Fitting set 29-b... Loss = 0.120158
Fitting set 30-a... Loss = 0.119135
Fitting set 30-b... Loss = 0.118139
Fitting set 31-a... Loss = 0.117173
Fitting set 31-b... Loss = 0.116213
Fitting set 32-a... Loss = 0.115311
Fitting set 32-b... Loss = 0.114430
Fitting set 33-a... Loss = 0.113554
Fitting set 33-b... Loss = 0.112672
Fitting set 34-a... Loss = 0.111832
Fitting set 34-b... Loss = 0.110993
Fitting set 35-a... Loss = 0.110203
Fitting set 35-b... Loss = 0.109420
Fitting set 36-a... Loss = 0.108674
Fitting set 36-b... Loss = 0.107918
Fitting set 37-a... Loss = 0.107198
Fitting set 37-b... Loss = 0.106458
Fitting set 38-a... Loss = 0.105749
Fitting set 38-b... Loss = 0.105067
Fitting set 39-a... Loss = 0.104410
Fitting set 39-b... Loss = 0.103764
Fitting set 40-a... Loss = 0.103141
Fitting set 40-b... Loss = 0.102499
Fitting set 41-a... Loss = 0.101859
Fitting set 41-b... Loss = 0.101279
Fitting set 42-a... Loss = 0.100686
Fitting set 42-b... Loss = 0.100075
Fitting set 43-a... Loss = 0.099509
Fitting set 43-b... Loss = 0.098956
Fitting set 44-a... Loss = 0.098396
Fitting set 44-b... Loss = 0.097852
Fitting set 45-a... Loss = 0.097302
Fitting set 45-b... Loss = 0.096763
Fitting set 46-a... Loss = 0.096223
Fitting set 46-b... Loss = 0.095674
Fitting set 47-a... Loss = 0.095153
Fitting set 47-b... Loss = 0.094651
Fitting set 48-a... Loss = 0.094162
Data set_nums shuffled
_____________________
EPOCH 1 -- COMPLETE
Validating...
Validating set 1-a... Loss = 0.078783
Validating set 1-b... Loss = 0.076317
Validating set 2-a... Loss = 0.075710
Validating set 2-b... Loss = 0.079148
Validating set 3-a... Loss = 0.081881
Validating set 3-b... Loss = 0.080691
Validating set 4-a... Loss = 0.077261
Validating set 4-b... Loss = 0.081151
Validating set 5-a... Loss = 0.079396
Validating set 5-b... Loss = 0.077392
Validating set 6-a... Loss = 0.078506
Validating set 6-b... Loss = 0.080747
Validating set 7-a... Loss = 0.078852
Validating set 7-b... Loss = 0.076874
Validating set 8-a... Loss = 0.079984
Validating set 8-b... Loss = 0.077159
Validating set 9-a... Loss = 0.077525
Validating set 9-b... Loss = 0.076241
Validating set 10-a... Loss = 0.078210
Validating set 10-b... Loss = 0.078955
Validating set 11-a... Loss = 0.080569
Validating set 11-b... Loss = 0.077822
Validating set 12-a... Loss = 0.079494
Validating set 12-b... Loss = 0.075832
Validating set 13-a... Loss = 0.079898
Validating set 13-b... Loss = 0.083832
Validating set 14-a... Loss = 0.077217
Validating set 14-b... Loss = 0.075610
Validating set 15-a... Loss = 0.082518
Validating set 15-b... Loss = 0.077477
Validating set 16-a... Loss = 0.081708
Validating set 16-b... Loss = 0.081968
Validating set 17-a... Loss = 0.080029
Validating set 17-b... Loss = 0.076852
Validating set 18-a... Loss = 0.076589
Validating set 18-b... Loss = 0.077327
Validating set 19-a... Loss = 0.079059
Validating set 19-b... Loss = 0.080847
Validating set 20-a... Loss = 0.075375
Validating set 20-b... Loss = 0.077266
Validating set 21-a... Loss = 0.082452
Validating set 21-b... Loss = 0.076946
Validating set 22-a... Loss = 0.078602
Validating set 22-b... Loss = 0.080538
Validating set 23-a... Loss = 0.077607
Validating set 23-b... Loss = 0.077118
Validating set 24-a... Loss = 0.078705
Validating set 24-b... Loss = 0.076103
Validating set 25-a... Loss = 0.077949
Validating set 25-b... Loss = 0.079300
Validating set 26-a... Loss = 0.076988
Validating set 26-b... Loss = 0.080871
Validating set 27-a... Loss = 0.083130
Validating set 27-b... Loss = 0.078603
Validating set 28-a... Loss = 0.077575
Validating set 28-b... Loss = 0.083491
Validating set 29-a... Loss = 0.078386
Validating set 29-b... Loss = 0.077624
Validating set 30-a... Loss = 0.077397
Validating set 30-b... Loss = 0.079600
Validating set 31-a... Loss = 0.079063
Validating set 31-b... Loss = 0.081749
Validating set 32-a... Loss = 0.078600
Validating set 32-b... Loss = 0.078188
Validating set 33-a... Loss = 0.081100
Validating set 33-b... Loss = 0.082994
Validating set 34-a... Loss = 0.079658
Validating set 34-b... Loss = 0.080738
Validating set 35-a... Loss = 0.079397
Validating set 35-b... Loss = 0.076358
Validating set 36-a... Loss = 0.079430
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M3__model-nadam__min.079
TrainGenerator state saved
Model report generated and saved
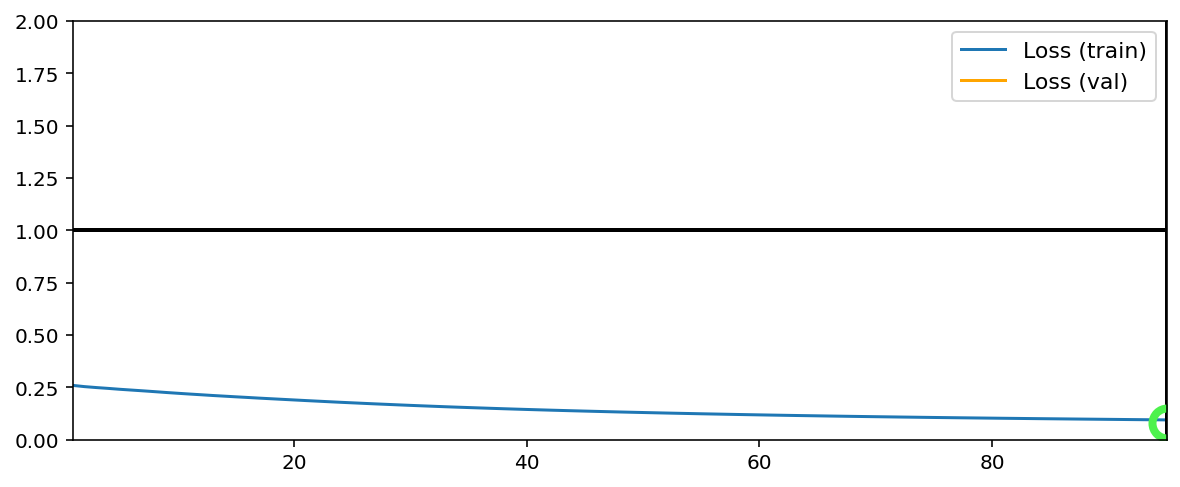
Training has concluded.
User batch_size=256, file batch_size=128¶
[6]:
C['datagen' ]['batch_size'] = 256
C['val_datagen']['batch_size'] = 256
C['model']['batch_shape'] = (256, 28, 28, 1)
[7]:
tg = init_session(C, make_autoencoder)
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
48 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
36 set nums inferred; if more are expected, ensure file names contain a common substring w/ a number (e.g. 'train1.npy', 'train2.npy', etc)
DataGenerator initiated
NOTE: will exclude `labels` from saving when `input_as_labels=True`; to keep 'labels', add '{labels}'to `saveskip_list` instead
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 48 files with matching format
................................................ finished, w/ 6144 total samples
Train initial data prepared
Preloading superbatch ... WARNING: multiple file extensions found in `path`; only .npy will be used
Discovered 36 files with matching format
.................................... finished, w/ 4608 total samples
Val initial data prepared
Logging ON; directory (new): C:\deeptrain\examples\dir\logs\M4__model-nadam__min999.000
[8]:
tg.train()
Fitting set 1+2... Loss = 0.278780
Fitting set 3+4... Loss = 0.271617
Fitting set 5+6... Loss = 0.266600
Fitting set 7+8... Loss = 0.261748
Fitting set 9+10... Loss = 0.257241
Fitting set 11+12... Loss = 0.253015
Fitting set 13+14... Loss = 0.248581
Fitting set 15+16... Loss = 0.244207
Fitting set 17+18... Loss = 0.239981
Fitting set 19+20... Loss = 0.235842
Fitting set 21+22... Loss = 0.231791
Fitting set 23+24... Loss = 0.227870
Fitting set 25+26... Loss = 0.224052
Fitting set 27+28... Loss = 0.220263
Fitting set 29+30... Loss = 0.216646
Fitting set 31+32... Loss = 0.213080
Fitting set 33+34... Loss = 0.209693
Fitting set 35+36... Loss = 0.206401
Fitting set 37+38... Loss = 0.203193
Fitting set 39+40... Loss = 0.200143
Fitting set 41+42... Loss = 0.197141
Fitting set 43+44... Loss = 0.194222
Fitting set 45+46... Loss = 0.191372
Fitting set 47+48... Loss = 0.188653
Data set_nums shuffled
_____________________
EPOCH 1 -- COMPLETE
Validating...
Validating set 1+2... Loss = 0.208901
Validating set 3+4... Loss = 0.208795
Validating set 5+6... Loss = 0.208823
Validating set 7+8... Loss = 0.208704
Validating set 9+10... Loss = 0.208591
Validating set 11+12... Loss = 0.208970
Validating set 13+14... Loss = 0.208594
Validating set 15+16... Loss = 0.208772
Validating set 17+18... Loss = 0.209147
Validating set 19+20... Loss = 0.208776
Validating set 21+22... Loss = 0.208982
Validating set 23+24... Loss = 0.208814
Validating set 25+26... Loss = 0.208499
Validating set 27+28... Loss = 0.208881
Validating set 29+30... Loss = 0.208739
Validating set 31+32... Loss = 0.208822
Validating set 33+34... Loss = 0.208793
Validating set 35+36... Loss = 0.208779
TrainGenerator state saved
Model report generated and saved
Best model saved to C:\deeptrain\examples\dir\models\M4__model-nadam__min.209
TrainGenerator state saved
Model report generated and saved
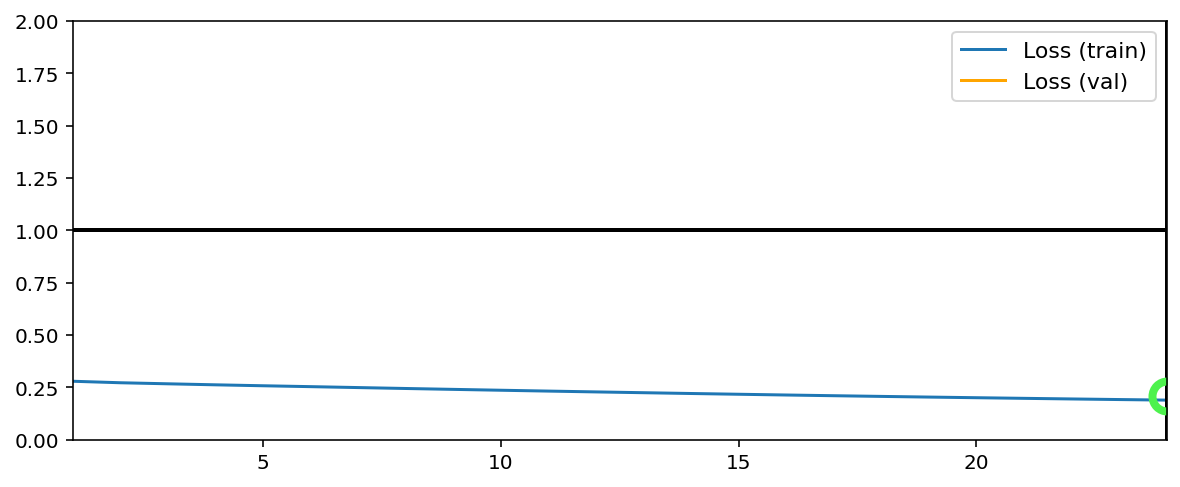
Training has concluded.
We can see the difference in the two settings through sets logging:
batch_size=64: aset_numis split into'a'and'b'batch_size=256:set_num1 + set_num2, combining two files
Faster SSD Loading¶
- Save larger
batch_sizeon disk (e.g. 512) than is used (e.g. 32). - Larger files much better utilize an SSD’s read speed via parallelism.
batch_sizeon file can be as large as RAM permits.